SQL에서 숫자의 자리 수를 맞춰서 버리기 위해서는 truncate 함수를 사용한다.
예시를 통해 살펴보자. 아래와 같이 height 테이블을 만든다.
코드를 실행하면 아래와 같이 테이블이 생성되는 것을 확인할 수 있다.

truncate(숫자, 자릿 수)를 사용하여 숫자를 바꿔보자. 아래와 같이 자릿 수에 "1"을 입력해보자.
결과는 아래와 같다.
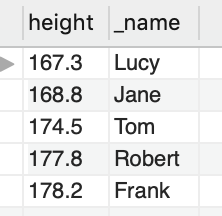
소수점 "1"번째 자리를 기준으로 그 아래의 숫자는 버림을 확인할 수 있다.
이번에는 자릿 수 부분에 "0"을 대입해보자.

이번에는 자릿 수 부분에 "-1"을 대입해보자.

truncate함수는 반올림이 아니라, 버림이다. 혼동하지 말자.
끝.
예시를 통해 살펴보자. 아래와 같이 height 테이블을 만든다.
1 2 3 4 5 6 7 8 9 | CREATE TABLE HEIGHT(height float PRIMARY KEY, Name text); INSERT INTO HEIGHT VALUES(174.52,'Tom'); INSERT INTO HEIGHT VALUES(167.33,'Lucy'); INSERT INTO HEIGHT VALUES(178.27,'Frank'); INSERT INTO HEIGHT VALUES(168.89,'Jane'); INSERT INTO HEIGHT VALUES(177.80,'Robert'); SELECT * FROM HEIGHT; |
코드를 실행하면 아래와 같이 테이블이 생성되는 것을 확인할 수 있다.
truncate(숫자, 자릿 수)를 사용하여 숫자를 바꿔보자. 아래와 같이 자릿 수에 "1"을 입력해보자.
1 2 3 | SELECT truncate(height, 1) as height, _name FROM height ; |
결과는 아래와 같다.
소수점 "1"번째 자리를 기준으로 그 아래의 숫자는 버림을 확인할 수 있다.
이번에는 자릿 수 부분에 "0"을 대입해보자.
1 2 3 | SELECT truncate(height, 0) as height, _name FROM height ; |
숫자 "0"을 대입하면 아래와 같이 소수점 "0"번째 자리, 즉 정수를 기준으로 그 아래는 버리게 된다.
이번에는 자릿 수 부분에 "-1"을 대입해보자.
1 2 3 | SELECT truncate(height, -1) as height, _name FROM height ; |
숫자 "-1"을 대입하면 아래와 같이 소수점 "-1"번째 자리, 즉 "10"을 기준으로 그 아래는 버리게 된다.
truncate함수는 반올림이 아니라, 버림이다. 혼동하지 말자.
끝.
댓글
댓글 쓰기