0. DAU(Daily Active Users, 일별 활성 사용자)는 앱 또는 웹을 사용한 사용자 수를 일별 집계한 값이다.
게임 앱이라고 가정한다면, 일별 게임 플레이한 유저 수가 DAU라 할 수 있다. 유저 수는 중복을 제거한다. DAU에 대한 자세한 설명은 위키피디아에서 확인할 수 있다.
1. 먼저 매일 게임을 플레이한 유저를 기록하는 PLAYS라는 가상의 DataFrame이 있다고 하자.
Pandas 라이브러리를 이용해 user_id와 플레이한 date가 기록되어 있는 간단한 샘플 데이터프레임을 아래와 같이 만든다.
tail() 메서드를 이용해 아래와 같이 PLAYS 데이터프레임이 잘 만들어진 것을 확인할 수 있다.
Jupyter Notebook을 이용하면 바로 확인할 수 있다.

2. DAU는 "일별로 유저 수 집계", "중복 유저 제거" 2가지 조건을 충족시켜야 한다.
즉 날짜(created_at)를 기준으로 user_id 수를 집계 하되, 중복 유저는 제거하고 집계해야 한다.
"groupby(['created_at'])"를 이용하여 날짜를 기준으로 집계한다.
"agg({'user_id': pd.Series.unique})"를 이용하여 groupby의 기준에 의한 user_id의 수를 집계한다.
중복을 제거하지 않고 count하고 싶으면, count 메서드를 사용한다.
"agg({'user_id': 'count'})"와 같이 작성하면 된다. count의 양쪽에 따옴표(')를 붙여야 한다.
user_id의 중복을 제거하고, unique한 값만 사용하기 위해 "pd.Series.unique"로 작성하였다.
두 번째 줄의 "rename" 메서드는 칼럼의 이름을 재지정하기 위함이다. 데이터프레임의 칼럼명을 created_at -> date, user_id -> dau로 재지정하였다.
위 조건을 대입한 코드는 아래와 같다.
코드를 실행하면 아래와 같이 DAU가 산출된다.
마지막 4번째 줄의 "dau" 코드는 산출된 DAU 데이터프레임을 Jupyter Notebook에서 확인하기 위해 작성한 것이다.
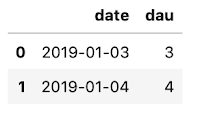
1월 3일에는 3명, 1월 4일에는 4명의 유저가 DAU로 집계됨을 확인할 수 있다.
SQL을 이용해 DAU를 산출하고 싶다면, "SQL - DAU 산출" 포스팅에서 쿼리를 확인할 수 있다.
끝.
게임 앱이라고 가정한다면, 일별 게임 플레이한 유저 수가 DAU라 할 수 있다. 유저 수는 중복을 제거한다. DAU에 대한 자세한 설명은 위키피디아에서 확인할 수 있다.
1. 먼저 매일 게임을 플레이한 유저를 기록하는 PLAYS라는 가상의 DataFrame이 있다고 하자.
Pandas 라이브러리를 이용해 user_id와 플레이한 date가 기록되어 있는 간단한 샘플 데이터프레임을 아래와 같이 만든다.
1 2 3 4 5 6 7 8 | import pandas as pd user_id = ['1', '4', '6', '1', '2', '8', '10', '1'] created_at = ['2019-01-03', '2019-01-03', '2019-01-03', '2019-01-03', '2019-01-04', '2019-01-04', '2019-01-04', '2019-01-04'] plays = pd.DataFrame({'user_id': user_id, 'created_at': created_at}) plays.tail() |
tail() 메서드를 이용해 아래와 같이 PLAYS 데이터프레임이 잘 만들어진 것을 확인할 수 있다.
Jupyter Notebook을 이용하면 바로 확인할 수 있다.

즉 날짜(created_at)를 기준으로 user_id 수를 집계 하되, 중복 유저는 제거하고 집계해야 한다.
"groupby(['created_at'])"를 이용하여 날짜를 기준으로 집계한다.
"agg({'user_id': pd.Series.unique})"를 이용하여 groupby의 기준에 의한 user_id의 수를 집계한다.
중복을 제거하지 않고 count하고 싶으면, count 메서드를 사용한다.
"agg({'user_id': 'count'})"와 같이 작성하면 된다. count의 양쪽에 따옴표(')를 붙여야 한다.
user_id의 중복을 제거하고, unique한 값만 사용하기 위해 "pd.Series.unique"로 작성하였다.
두 번째 줄의 "rename" 메서드는 칼럼의 이름을 재지정하기 위함이다. 데이터프레임의 칼럼명을 created_at -> date, user_id -> dau로 재지정하였다.
위 조건을 대입한 코드는 아래와 같다.
1 2 3 4 | dau = plays.groupby(['created_at'], as_index=False).agg({'user_id': pd.Series.nunique}) dau = dau.rename(index=str, columns={'created_at': 'date', 'user_id': 'dau'}) dau |
코드를 실행하면 아래와 같이 DAU가 산출된다.
마지막 4번째 줄의 "dau" 코드는 산출된 DAU 데이터프레임을 Jupyter Notebook에서 확인하기 위해 작성한 것이다.

1월 3일에는 3명, 1월 4일에는 4명의 유저가 DAU로 집계됨을 확인할 수 있다.
SQL을 이용해 DAU를 산출하고 싶다면, "SQL - DAU 산출" 포스팅에서 쿼리를 확인할 수 있다.
끝.
댓글
댓글 쓰기